Fehler-in-den-Variablen-Modell
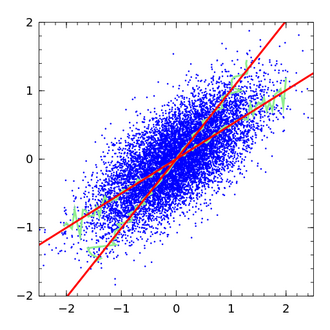
In der Statistik sind Fehler-in-den-Variablen-Modelle, auch Messfehlermodelle genannt, Regressionsmodelle für Regression mit stochastischen Regressoren, in der entweder die Antwortvariable oder einige erklärende Variablen mit Fehlern gemessen werden.[1]
Klassisches Fehler-in-den-Variablen-Modell
Gegeben sei im einfachsten Fall ein einfaches lineares Regressionsmodell[2]:
 .
.
Im klassischen Fehler-in-den-Variablen-Modell wird angenommen, dass
 nur mit zufälligem Fehler
nur mit zufälligem Fehler
 beobachtet werden kann, d. h. man hat dann den stochastischen Regressor
beobachtet werden kann, d. h. man hat dann den stochastischen Regressor
 . Für die Messfehler
wird angenommen, dass sie unabhängig und identisch verteilt
mit Erwartungswert null und Varianz
. Für die Messfehler
wird angenommen, dass sie unabhängig und identisch verteilt
mit Erwartungswert null und Varianz
 , unkorreliert mit
und unkorreliert mit der Störgröße
, unkorreliert mit
und unkorreliert mit der Störgröße
 sind.
sind.
Konsequenzen von Fehlern in den Variablen
Messfehler in den erklärenden Variablen führen dazu, dass die gewöhnliche Kleinste-Quadrate-Schätzung nicht konsistent ist. Intuitiv betrachtet kommt es während des Trainings des Modells zu einer Fehlerfortpflanzung, was ohne weitere Gegenmaßnahmen die Qualität des Modells beeinträchtigen kann.
Einzelnachweise
- ↑ Jeffrey Marc Wooldridge: Introductory econometrics: A modern approach. 4. Auflage. Nelson Education, 2015, S. 848.
- ↑ Schneeweiß, H.: Ökonometrie, Physica Verlag 1990 (4. Auflage) Kapitel 7
 (3. Auflage 1978)
(Google Books)
(3. Auflage 1978)
(Google Books)


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 03.10. 2025