Schnelle Fourier-Transformation
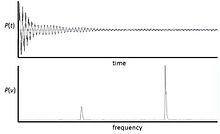
Die schnelle Fourier-Transformation (englisch fast Fourier transform, daher meist FFT abgekürzt) ist ein Algorithmus zur effizienten Berechnung der diskreten Fourier-Transformation (DFT). Mit ihr kann ein digitales Signal in seine Frequenzanteile zerlegt und diese dann analysiert werden.
Analog gibt es für die diskrete inverse Fourier-Transformation die inverse schnelle Fourier-Transformation (IFFT). Es kommen bei der IFFT die gleichen Algorithmen, aber mit konjugierten Koeffizienten zur Anwendung.
Die FFT hat zahlreiche Anwendungen (siehe auch unten) im Bereich der Ingenieurwissenschaften, der Naturwissenschaften und der angewandten Mathematik. Außerdem kommt sie in Mobilfunktechnologien wie UMTS und LTE und bei der drahtlosen Datenübertragung zum Einsatz, etwa in der WLAN-Funknetztechnik.
Die FFT gehört zu den Teile-und-herrsche-Verfahren, sodass – im Gegensatz zur direkten Berechnung – zuvor berechnete Zwischenergebnisse wiederverwendet und dadurch arithmetische Rechenoperationen eingespart werden können. Das bekannteste Verfahren wird James Cooley und John W. Tukey zugeschrieben, die es 1965 veröffentlichten. Genau genommen wurde eine Form des Algorithmus bereits 1805 von Carl Friedrich Gauß entworfen, der ihn zur Berechnung der Flugbahnen der Asteroiden (2) Pallas und (3) Juno verwendete. Zum ersten Mal publiziert wurde eine Variante des Algorithmus von Carl Runge im Jahre 1903 und 1905. Darüber hinaus wurden eingeschränkte Formen des Algorithmus mehrfach vor Cooley und Tukey entwickelt, so z.B. von Irving John Good (1960). Nach Cooley und Tukey hat es darüber hinaus zahlreiche Verbesserungsvorschläge und Variationen gegeben, so etwa von Georg Bruun, C. M. Rader und Leo I. Bluestein.
Informelle Beschreibung des Algorithmus (Cooley und Tukey)
Der Algorithmus von Cooley und Tukey ist ein klassisches Teile-und-herrsche-Verfahren. Voraussetzung für seine Anwendung ist, dass die Anzahl der Stützstellen bzw. Abtastpunkte eine Zweierpotenz ist. Da die Anzahl solcher Punkte im Rahmen von Messverfahren jedoch im Allgemeinen frei gewählt werden kann, handelt es sich dabei nicht um eine gravierende Einschränkung.
Der Algorithmus basiert auf der Beobachtung, dass die Berechnung einer DFT der Größe 2n in zwei Berechnungen einer DFT der Größe n zerlegbar ist (über den Vektor mit den Einträgen der geraden bzw. der ungeraden Indizes), wobei die beiden Teilergebnisse nach der Transformation wieder zu einer Fouriertransformation der Größe 2n zusammenzufassen sind.
Da die Berechnung einer DFT der halben Länge nur ein Viertel der komplexen
Multiplikationen und Additionen der originalen DFT benötigt, und je nach Länge
des Ausgangsvektors diese Vorschrift mehrfach hintereinander anwendbar ist,
erlaubt die rekursive Anwendung dieser
Grundidee schließlich eine Berechnung in  Zeit; zur Einsparung von trigonometrischen
Rechenoperationen können bei der FFT zusätzlich die Eigenschaften der Einheitswurzeln aus der
Fouriermatrix ausgenutzt werden.
Zeit; zur Einsparung von trigonometrischen
Rechenoperationen können bei der FFT zusätzlich die Eigenschaften der Einheitswurzeln aus der
Fouriermatrix ausgenutzt werden.
Algorithmus von Cooley und Tukey
Die diskrete
Fouriertransformation (DFT) eines Vektors  der Dimension
der Dimension  lautet:
lautet:
 .
.
Die Einträge mit geraden Indizes werden notiert als

und deren DFT der Dimension  als
als  .
.
Entsprechend seien die Einträge mit ungeraden Indizes notiert als

mit DFT  .
.
Dann folgt:
![{\begin{aligned}f_{m}&=\sum _{{k=0}}^{{n-1}}x_{{2k}}e^{{-{\frac {2\pi i}{2n}}m(2k)}}+\sum _{{k=0}}^{{n-1}}x_{{2k+1}}e^{{-{\frac {2\pi i}{2n}}m(2k+1)}}\\[0.5em]&=\sum _{{k=0}}^{{n-1}}x'_{k}e^{{-{\frac {2\pi i}{n}}mk}}+e^{{-{\frac {\pi i}{n}}m}}\sum _{{k=0}}^{{n-1}}x''_{k}e^{{-{\frac {2\pi i}{n}}mk}}\\[0.5em]&={\begin{cases}f'_{m}+e^{{-{\frac {\pi i}{n}}m}}f''_{m}&{\text{ falls }}m<n\\[0.5em]f'_{{m-n}}-e^{{-{\frac {\pi i}{n}}(m-n)}}f''_{{m-n}}&{\text{ falls }}m\geq n\end{cases}}\end{aligned}}](/svg/6b17753747aee387d3f9dc428c3d33eb8c327b4c.svg)
Mit der Berechnung von  und
und  (
( )
ist sowohl
)
ist sowohl  ,
als auch
,
als auch  bestimmt. Der Rechenaufwand hat sich durch diese Zerlegung also praktisch
halbiert.
bestimmt. Der Rechenaufwand hat sich durch diese Zerlegung also praktisch
halbiert.
Mathematische Beschreibung (allgemeiner Fall)
In der Mathematik wird die schnelle diskrete Fouriertransformation in einem wesentlich allgemeineren Kontext behandelt:
Sei  ein kommutativer
unitärer
Ring. In
sei die Zahl
ein kommutativer
unitärer
Ring. In
sei die Zahl  eine Einheit
(d. h. invertierbar); ferner sei
eine Einheit
(d. h. invertierbar); ferner sei  eine
eine  -te
Einheitswurzel mit
-te
Einheitswurzel mit  .
Zum Beispiel ist im Restklassenring
.
Zum Beispiel ist im Restklassenring
 mit
mit  ,
,
 ,
d ungerade (das ist gleichbedeutend mit der Forderung „teilerfremd zu
“),
,
d ungerade (das ist gleichbedeutend mit der Forderung „teilerfremd zu
“),
das Element  eine solche Einheitswurzel, die entsprechende FFT wird im
Schönhage-Strassen-Algorithmus
verwendet.
eine solche Einheitswurzel, die entsprechende FFT wird im
Schönhage-Strassen-Algorithmus
verwendet.
Dann lässt sich im Modul
 zu
zu  die diskrete Fouriertransformierte
die diskrete Fouriertransformierte  mit
mit

wie folgt optimiert berechnen:
Zunächst stellen wir die Indizes  und
und  wie folgt dual dar:
wie folgt dual dar:
 .
.
Damit haben wir folgende Rekursion:
 ,
, .
.
Wegen

erhalten wir hieraus die diskrete Fouriertransformierte  .
.
Komplexität
Diese klassische Variante der FFT nach Cooley und Tukey ist im Gegensatz zur DFT nur durchführbar, wenn die Länge des Eingangsvektors einer Zweierpotenz entspricht. Die Anzahl der Abtastpunkte kann also beispielsweise 1, 2, 4, 8, 16, 32 usw. betragen. Man spricht hier von einer Radix-2-FFT. Andere Längen sind mit den unten angeführten alternativen Algorithmen möglich.
Aus obiger Rekursion ergibt sich folgende Rekursionsgleichung für die Laufzeit der FFT:

Hierbei beschreibt der Term  den Aufwand, um die Ergebnisse mit einer Potenz der Einheitswurzel zu
multiplizieren und die Ergebnisse zu addieren. Es werden N Paare von
Zahlen addiert und N/2 Zahlen mit Einheitswurzeln multipliziert.
Insgesamt ist f(N) also linear beschränkt:
den Aufwand, um die Ergebnisse mit einer Potenz der Einheitswurzel zu
multiplizieren und die Ergebnisse zu addieren. Es werden N Paare von
Zahlen addiert und N/2 Zahlen mit Einheitswurzeln multipliziert.
Insgesamt ist f(N) also linear beschränkt:

Mit dem Master-Theorem ergibt sich eine Laufzeit von:

Die Struktur des Datenflusses kann durch einen Schmetterlingsgraphen beschrieben werden, der die Reihenfolge der Berechnung festlegt.
Implementierung als rekursiver Algorithmus
Die direkte Implementierung der FFT in Pseudocode nach obiger Vorschrift besitzt die Form eines rekursiven Algorithmus:
- Das Feld mit den Eingangswerten wird einer Funktion als Parameter übergeben, die es in zwei halb so lange Felder (eins mit den Werten mit geradem und eins mit den Werten mit ungeradem Index) aufteilt.
- Diese beiden Felder werden nun an neue Instanzen dieser Funktion übergeben.
- Am Ende gibt jede Funktion die FFT des ihr als Parameter übergebenen Feldes zurück. Diese beiden FFTs werden nun, bevor eine Instanz der Funktion beendet wird, nach der oben abgebildeten Formel zu einer einzigen FFT kombiniert - und das Ergebnis an den Aufrufer zurückgegeben.
Dies wird nun fortgeführt, bis das Argument eines Aufrufs der Funktion nur noch aus einem einzigen Element besteht (Rekursionsabbruch): Die FFT eines einzelnen Wertes ist (er besitzt sich selbst als Gleichanteil, und keine weiteren Frequenzen) er selbst. Die Funktion, die nur noch einen einzigen Wert als Parameter erhält, kann also ganz ohne Rechnung die FFT dieses Wertes zurückliefern – die Funktion, die sie aufgerufen hat, kombiniert die beiden jeweils 1 Punkt langen FFTs, die sie zurückerhält, die Funktion, die diese wiederum aufgerufen hat, die beiden 2-Punkte-FFTs, und so weiter.









Der Geschwindigkeitsvorteil der FFT gegenüber der DFT kann anhand dieses Algorithmus gut abgeschätzt werden:
- Um die FFT eines
 Elemente langen Vektors zu berechnen, sind bei Verwendung dieses Algorithmus
n Rekursionsebenen nötig. Dabei verdoppelt sich in jeder Ebene die
Anzahl der zu berechnenden Vektoren - während sich deren Länge jeweils
halbiert, so dass am Ende in jeder bis auf die letzte Rekursionsebene genau
komplexe Multiplikationen und Additionen notwendig sind. Die Gesamtzahl der
Additionen und Multiplikationen beträgt also
Elemente langen Vektors zu berechnen, sind bei Verwendung dieses Algorithmus
n Rekursionsebenen nötig. Dabei verdoppelt sich in jeder Ebene die
Anzahl der zu berechnenden Vektoren - während sich deren Länge jeweils
halbiert, so dass am Ende in jeder bis auf die letzte Rekursionsebene genau
komplexe Multiplikationen und Additionen notwendig sind. Die Gesamtzahl der
Additionen und Multiplikationen beträgt also 
- Im Gegensatz benötigt die DFT für denselben Eingangsvektor
 komplexe Multiplikationen und Additionen.
komplexe Multiplikationen und Additionen.
Implementierung als nichtrekursiver Algorithmus
Die Implementierung eines rekursiven Algorithmus ist im Regelfall vom Ressourcenverbrauch her nicht ideal, da die vielen dabei notwendigen Funktionsaufrufe Rechenzeit und Speicher für das Merken der Rücksprungadressen benötigen. In der Praxis wird daher meist ein nichtrekursiver Algorithmus verwendet, der gegenüber der hier abgebildeten, auf einfaches Verständnis optimierten Form je nach Anwendung noch optimiert werden kann:
- Wenn im obigen Algorithmus zuerst die beiden Hälften des Feldes miteinander vertauscht werden, und dann die beiden Hälften dieser Hälften, usw. – dann ist das Ergebnis am Ende dasselbe, als würden alle Elemente des Feldes von 0 aufsteigend nummeriert werden und anschließend die Reihenfolge der Bits der Nummern der Felder umgekehrt.
- Nachdem die Eingangswerte solchermaßen umsortiert sind, bleibt nur noch
die Aufgabe, die einzelnen kurzen FFTs von der letzten Rekursionsebene nach
außen zu längeren FFTs zu kombinieren, z.B. in Form dreier
ineinandergeschachtelter Schleifen:
- Die äußerste Schleife zählt die Rekursionsebene
 durch (von 0 bis N-1).
durch (von 0 bis N-1). - Die nächste Schleife zählt die
 FFT-Abschnitte durch, in der die FFT in dieser Rekursionsebene noch
aufgeteilt ist. Der Zähler dieser Schleife wird im Folgenden als
FFT-Abschnitte durch, in der die FFT in dieser Rekursionsebene noch
aufgeteilt ist. Der Zähler dieser Schleife wird im Folgenden als  bezeichnet.
bezeichnet. - Die innerste Schleife zählt das Element innerhalb eines FFT-Abschnittes
(im Folgenden
 genannt) durch (von 0 bis
genannt) durch (von 0 bis  )
) - In der innersten dieser Schleifen werden nun immer die beiden Samples mit den folgenden beiden Indizes:
- Die äußerste Schleife zählt die Rekursionsebene


- über einen Schmetterlingsgraph
kombiniert:

Alternative Formen der FFT
Neben dem oben dargestellten FFT-Algorithmus von Cooley und Tukey, auch Radix-2-Algorithmus genannt, existieren noch eine Reihe weiterer Algorithmen zur schnellen Fourier-Transformation. Die Varianten unterscheiden sich darin, wie bestimmte Teile des „naiven“ Algorithmus so umgeformt werden, dass weniger (Hochpräzisions-)Multiplikationen notwendig sind. Dabei gilt meist, dass die Reduktion in der Anzahl der Multiplikationen eine erhöhte Anzahl von Additionen sowie von gleichzeitig im Speicher zu haltenden Zwischenergebnissen hervorruft.
Im Folgenden sind übersichtsartig einige weitere Algorithmen dargestellt. Details und genaue mathematische Beschreibungen samt Herleitungen finden sich in der unten angegebenen Literatur.
Radix-4-Algorithmus
Der Radix-4-Algorithmus ist, analog dazu der Radix-8-Algorithmus oder allgemein Radix-2N-Algorithmus, eine Weiterentwicklung des obigen Radix-2-Algorithmus. Der Hauptunterschied besteht darin, dass die Anzahl der zu verarbeitenden Datenpunkte eine Potenz von 4 bzw. 2N darstellen muss. Die Verarbeitungstruktur bleibt dabei gleich, nur dass in dem Schmetterlingsgraph pro Element statt zwei Datenpfade vier bzw. acht und allgemein 2N Datenpfade miteinander verknüpft werden müssen. Der Vorteil besteht in einem weiter reduzierten Rechenaufwand und damit Geschwindigkeitsvorteil. So sind, verglichen mit dem obigen Algorithmus von Cooley und Tukey, bei dem Radix-4-Algorithmus ca. 25 % weniger Multiplikationen notwendig. Bei dem Radix-8-Algorithmus reduziert sich die Anzahl der Multiplikationen um ca. 40 %.
Nachteil dieser Verfahren ist die gröbere Struktur und ein aufwendiger Programmcode. So lassen sich mit Radix-4-Algorithmus nur Blöcke der Längen 4, 16, 64, 256, 1024, 4096, … verarbeiten. Bei dem Radix-8-Algorithmus sind die Einschränkungen analog zu sehen.
Winograd-Algorithmus
Bei diesem Algorithmus ist nur eine bestimmte, endliche Anzahl von
Stützstellen der Anzahl  möglich, nämlich:
möglich, nämlich:

wobei alle Kombinationen von Nj zulässig sind, bei denen die
verwendeten Nj teilerfremd
sind. Dadurch ist nur eine maximale Blocklänge von 5040 möglich. Die möglichen
Werte für
liegen aber in dem Bereich bis 5040 dichter auf der Zahlengeraden als die
Zweierpotenzen. Es ist damit eine bessere Feinabstimmung der Blocklänge möglich.
Aufgebaut wird der Algorithmus aus Basisblöcken der DFT, deren Längen mit
Nj korrespondieren. Bei diesem Verfahren wird zwar die Anzahl
der Multiplikationen gegenüber dem Radix-2-Algorithmus reduziert, gleichzeitig
steigt aber die Anzahl der notwendigen Additionen. Außerdem ist am Eingang
und Ausgang jeder DFT eine aufwendige Permutation der Daten notwendig,
die nach den Regeln des Chinesischen
Restsatzes gebildet wird.
Diese Art der schnellen Fourier-Transformation besitzt in praktischen Implementierungen dann Vorteile gegenüber der Radix-2-Methode, wenn der für die FFT verwendete Mikrocontroller keine eigene Multipliziereinheit besitzt und für die Multiplikationen sehr viel Rechenzeit aufgewendet werden muss. In heutigen Signalprozessoren mit eigenen Multipliziereinheiten hat dieser Algorithmus keine wesentliche Bedeutung mehr.
Primfaktor-Algorithmus
Dieser FFT-Algorithmus basiert auf ähnlichen Ideen wie der Winograd-Algorithmus, allerdings ist die Struktur einfacher und damit der Aufwand an Multiplikationen höher als beim Winograd-Algorithmus. Der wesentliche Vorteil bei der Implementierung liegt in der effizienten Ausnutzung des zur Verfügung stehenden Speichers durch optimale Anpassung der Blocklänge. Wenn in einer bestimmten Anwendung zwar eine schnelle Multipliziereinheit verfügbar ist und gleichzeitig der Speicher knapp, kann dieser Algorithmus optimal sein. Die Ausführungszeit ist bei ähnlicher Blocklänge mit der des Algorithmus von Cooley und Tukey vergleichbar.
Goertzel-Algorithmus
Der Goertzel-Algorithmus stellt eine besondere Form zur effizienten Berechnung einzelner Spektralkomponenten dar und ist bei der Berechnung von nur einigen wenigen Spektralanteilen (engl. Bins) effizienter als alle blockbasierenden FFT-Algorithmen, welche immer das komplette diskrete Spektrum berechnen.
Chirp-z-Transformation
Bluestein-FFT-Algorithmus für Datenmengen beliebiger Größe (einschließlich Primzahlen).
Die inverse FFT
Die Inverse der diskreten Fourier-Transformation (DFT) stimmt bis auf den Normierungsfaktor und ein Vorzeichen mit der DFT überein. Da die schnelle Fourier-Transformation ein Algorithmus zur Berechnung der DFT ist, gilt dies dann natürlich auch für die FFT.
Anwendung
Die Anwendungsgebiete der FFT sind so vielseitig, dass hier nur eine Auswahl wiedergegeben werden kann:
- Computeralgebra
- Implementierung schneller, Polynome
verarbeitender Algorithmen (z.B. Polynommultiplikation in
 )
)
- Implementierung schneller, Polynome
verarbeitender Algorithmen (z.B. Polynommultiplikation in
- Finanzmathematik
- Die Berechnung von Optionspreisen (vgl. Carr / Madan 1999)
- Signalanalyse
- Akustik (Audiomessungen). Eine relativ triviale Anwendung sind viele Gitarrenstimmgeräte oder ähnliche Programme, die von der hohen Geschwindigkeit der FFT profitieren.
- Berechnung von Spektrogrammen (Diagramme mit der Darstellung der Amplituden von den jeweiligen Frequenzanteilen)
- Rekonstruktion des Bildes beim Kernspintomographen oder der Analyse von Kristallstrukturen mittels Röntgenstrahlen, bei denen jeweils die Fouriertransformierte des gewünschten Bildes, bzw. das Quadrat dieser Fouriertransformierten entsteht.
- Messtechnik / allgemein
- Digitale Netzwerkanalysatoren, die das Verhalten einer Schaltung, eines Bauelementes oder einer Leitung auf einer Leiterbahn bei Betrieb mit beliebigen Frequenzgemischen zu ermitteln versuchen.
- Digitale
Signalverarbeitung
- Synthese von Audiosignalen aus einzelnen Frequenzen über die inverse FFT
- Zur Reduzierung des Berechnungsaufwandes bei der zirkularen Faltung im Zeitbereich von FIR-Filtern und Ersatz durch die schnelle Fouriertransformation und einfache Multiplikationen im Frequenzbereich. (siehe auch Schnelle Faltung). Die Schnelle Faltung bietet z.B. die Möglichkeit, beliebige Audio- oder ähnliche Signale mit wenig Rechenaufwand durch auch sehr komplexe Filter (Equalizer, etc.) zu transportieren.
- Kompressionsalgorithmen verwenden oft die FFT oder, wie das bekannte MP3-Format, die mit ihr verwandte diskrete Kosinustransformation. Die FFT von Bildern oder Tönen ergibt oft nur relativ wenige Frequenzanteile mit hohen Amplituden. Dies ist von Vorteil, wenn ein Verfahren zur Speicherung der Ergebnisse verwendet wird, das für die Darstellung niedriger Zahlen weniger Bits benötigt, wie z.B. die Huffman-Kodierung. In anderen Fällen wird ausgenutzt, dass einige der Frequenzen weggelassen werden können, ohne das Ergebnis stark zu beeinträchtigen, so dass der Datenstrom reduziert werden kann.
- Telekommunikation
- Längstwellenempfang mit dem PC
- Breitbanddatenübertragung per OFDM, die Grundlage für ADSL und WLAN (Internet), die verschiedenen DVB-Übertragungsstandards für digitales Fernsehen z.B. über Antenne, Kabel und TV-Satellit, DRM, DAB (Radio) und LTE (Mobilfunk der 4. Generation) ist. Hier wird die hohe Geschwindigkeit der Datenübertragung dadurch erreicht, dass viele relativ langsame Datenübertragungen auf vielen Trägerfrequenzen gleichzeitig betrieben werden. Das komplexe Signal, das durch Überlagerung der einzelnen Signale entsteht, wird dann von der Gegenstelle mittels der FFT wieder in einzelne Signalträger zerlegt.


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 28.05. 2023