Standardabweichung (Wahrscheinlichkeitstheorie)
Die Standardabweichung, auch Streuung genannt, ist eine reelle Zahl in der Stochastik, die der Verteilung einer Zufallsvariable oder einer Wahrscheinlichkeitsverteilung zugeordnet werden kann. Die Standardabweichung ist wie die Varianz ein Streuungsmaß und ist mit dieser eng verwandt, besitzt aber im Gegenteil zu ihr dieselbe Dimension wie die Zufallsvariable. Besitzt eine Zufallsvariable eine große Standardabweichung, so bedeutet dies, dass sie weit um den Erwartungswert streut in dem Sinne, dass es wahrscheinlicher ist, Werte zu erhalten, welche weit vom Erwartungswert entfernt liegen. Ferner eignet sich die Standardabweichung zur Quantifizierung von Unsicherheit bei Entscheidungen unter Risiko und ist somit ein Risikomaß.
Bei einigen Wahrscheinlichkeitsverteilungen, insbesondere der Normalverteilung, können aus der Standardabweichung direkt Wahrscheinlichkeiten berechnet werden. So befinden sich bei der Normalverteilung immer ca. 68% der Wahrscheinlichkeit im Intervall von der Breite von zwei Standardabweichungen um den Erwartungswert. Beispiel hierfür ist der Intelligenzquotient: Er ist auf Erwartungswert 100 und Standardabweichung 15 normiert, daher besitzen ca. 68% aller Menschen einen Intelligenzquotienten zwischen 85 und 115.
Von der hier besprochenen Standardabweichung sollte die empirische Standardabweichung unterschieden werden. Sie ist eine Kennzahl einer Stichprobe, also von mehreren Messwerten. Die hier besprochene Standardabweichung hingegen ist ein Kennzahl einer abstrakten (Mengen-)Funktion.
Als Abkürzung findet man neben  (sprich: „Sigma“) in Anwendungen insbesondere für die empirische
Standardabweichung oft s oder SD (für englisch
standard deviation), sowie m.F.
für mittlerer Fehler. In der angewandten Statistik findet man häufig die
Kurzschreibweise der Art „ø 21 ± 4“, was als „Mittelwert 21 mit einer
Standardabweichung von 4“ zu lesen ist. (Das Plusminuszeichen wird auch bei der
Angabe von Toleranzen
oder von Streuintervallen
verwendet.)
(sprich: „Sigma“) in Anwendungen insbesondere für die empirische
Standardabweichung oft s oder SD (für englisch
standard deviation), sowie m.F.
für mittlerer Fehler. In der angewandten Statistik findet man häufig die
Kurzschreibweise der Art „ø 21 ± 4“, was als „Mittelwert 21 mit einer
Standardabweichung von 4“ zu lesen ist. (Das Plusminuszeichen wird auch bei der
Angabe von Toleranzen
oder von Streuintervallen
verwendet.)
Definition
Gegeben sei ein Wahrscheinlichkeitsraum
 und eine Zufallsvariable
und eine Zufallsvariable
 .
.
Es bezeichne  die Varianz
von
die Varianz
von  .
.
Ist die Varianz von
endlich, so heißt

die Standardabweichung oder die Streuung von
(bezüglich  ).
).
Bezeichnet  die Bildung des Erwartungswertes,
so lässt sich die Varianz berechnen durch
die Bildung des Erwartungswertes,
so lässt sich die Varianz berechnen durch

oder aufgrund des Verschiebungssatzes als nicht-zentrales-Moment durch
 .
.
Beispiele
Diskrete Gleichverteilung, Würfel
Die diskrete
Gleichverteilung auf den Zahlen  hat einen Erwartungswert
hat einen Erwartungswert
 .
.
Dies folgt aus der Gaußschen Summenformel. Mit dieser Summenformel folgt dann

und damit über den Verschiebungssatz
 .
.
Siehe hierzu auch Bestimmung der Varianz über die Wahrscheinlichkeitsfunktion. Aus der Varianz berechnet sich die Standardabweichung zu
 .
.
Das Ergebnis des Wurfes eines fairen sechsseitigen Würfels hat also beispielsweise den Erwartungswert 3,5 und eine Standardabweichung von etwa 1,7.
Binomialverteilung
Ist
binomialverteilt
mit Parametern  (Anzahl der Wiederholungen) und
(Anzahl der Wiederholungen) und  (Erfolgswahrscheinlichkeit), so gilt nach dieser
Rechnung
(Erfolgswahrscheinlichkeit), so gilt nach dieser
Rechnung  ,
und folglich für die Standardabweichung
,
und folglich für die Standardabweichung

Würfelt man beispielsweise 500 Mal mit einem fairen Würfel, so ist die Anzahl
der Einser binomialverteilt mit  und
und  .
Der Erwartungswert beträgt nach dieser
Rechnung
.
Der Erwartungswert beträgt nach dieser
Rechnung

und die Standardabweichung

Weil eine Binomialverteilung mit den obigen Parametern nähernd normalverteilt ist, lassen die unten stehenden Faustformeln also erwarten, dass in 68 % der Fälle die Anzahl der Einser zwischen 75 und 92 liegt und in 95 % der Fälle zwischen 67 und 100.
Standardabweichung der Normalverteilung
Eindimensionale Normalverteilungen
werden durch Angabe von Erwartungswert  und Varianz
und Varianz  vollständig beschrieben. Ist also
eine --verteilte
Zufallsvariable – in Symbolen
vollständig beschrieben. Ist also
eine --verteilte
Zufallsvariable – in Symbolen  –, so ist ihre Standardabweichung einfach
–, so ist ihre Standardabweichung einfach  .
.
Streuintervalle
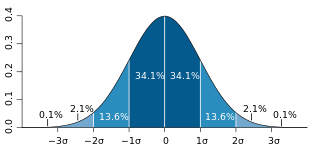 bei der Normalverteilung
bei der NormalverteilungAus der Tabelle der Standardnormalverteilung ist ersichtlich, dass für normalverteilte Zufallsgrößen jeweils ungefähr
- 68,3 % der Realisierungen im Intervall
 ,
, - 95,4 % im Intervall
 und
und - 99,7 % im Intervall

liegen. Da in der Praxis viele Zufallsgrößen annähernd normalverteilt sind, werden diese Werte aus der Normalverteilung oft als Faustformel benutzt. So wird beispielsweise σ oft als die halbe Breite des Intervalls angenommen, welches die mittleren zwei Drittel der Werte in einer Stichprobe umfasst, siehe Quantil.
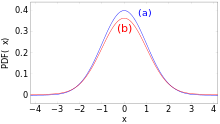
Diese Praxis ist aber nicht empfehlenswert, denn sie kann zu sehr großen
Fehlern führen. Zum Beispiel ist die Verteilung  optisch kaum von der Normalverteilung zu unterscheiden (siehe Bild), aber bei
ihr liegen im Intervall
optisch kaum von der Normalverteilung zu unterscheiden (siehe Bild), aber bei
ihr liegen im Intervall  92,5 % der Werte, wobei
92,5 % der Werte, wobei  die Standardabweichung von
bezeichnet. Solche kontaminierten
Normalverteilungen sind in der Praxis sehr häufig; das genannte Beispiel
beschreibt die Situation, wenn zehn Präzisionsmaschinen etwas herstellen, aber
eine davon schlecht justiert ist und zehnmal weniger präzise als die anderen
neun produziert.
die Standardabweichung von
bezeichnet. Solche kontaminierten
Normalverteilungen sind in der Praxis sehr häufig; das genannte Beispiel
beschreibt die Situation, wenn zehn Präzisionsmaschinen etwas herstellen, aber
eine davon schlecht justiert ist und zehnmal weniger präzise als die anderen
neun produziert.
Werte außerhalb der zwei- bis dreifachen Standardabweichung werden oft als Ausreißer behandelt. Ausreißer können ein Hinweis auf grobe Fehler der Datenerfassung sein. Es kann den Daten aber auch eine stark schiefe Verteilung zu Grunde liegen. Andererseits liegt bei einer Normalverteilung im Durchschnitt ca. jeder 20. Messwert außerhalb der zweifachen Standardabweichung und ca. jeder 500. Messwert außerhalb der dreifachen Standardabweichung.
Da der Anteil der Werte außerhalb der sechsfachen Standardabweichung mit ca. 2 ppb verschwindend klein wird, gilt ein solches Intervall als gutes Maß für eine nahezu vollständige Abdeckung aller Werte. Das wird im Qualitätsmanagement durch die Methode Six Sigma genutzt, indem die Prozessanforderungen Toleranzgrenzen von mindestens 6σ vorschreiben. Allerdings geht man dort von einer langfristigen Mittelwertverschiebung um 1,5 Standardabweichungen aus, so dass der zulässige Fehleranteil auf 3,4 ppm steigt. Dieser Fehleranteil entspricht einer viereinhalbfachen Standardabweichung (4,5σ). Ein weiteres Problem der 6σ-Methode ist, dass die 6σ-Punkte praktisch nicht bestimmbar sind. Bei unbekannter Verteilung (d.h. wenn es sich nicht ganz sicher um eine Normalverteilung handelt) grenzen zum Beispiel die Extremwerte von 1.400.000.000 Messungen ein 75%-Konfidenzintervall für die 6σ-Punkte ein.
| zσ | Prozent innerhalb | Prozent außerhalb | ppb außerhalb | Bruchteil außerhalb |
|---|---|---|---|---|
| 0,674 490σ | 50% | 50% | 500.000.000 ppb | 1 / 2 |
| 0,994 458σ | 68% | 32% | 320.000.000 ppb | 1 / 3,125 |
| 1σ | 68,268 9492% | 31,731 0508% | 317.310.508 ppb | 1 / 3,151 4872 |
| 1,281 552σ | 80% | 20% | 200.000.000 ppb | 1 / 5 |
| 1,644 854σ | 90% | 10% | 100.000.000 ppb | 1 / 10 |
| 1,959 964σ | 95% | 5% | 50.000.000 ppb | 1 / 20 |
| 2σ | 95,449 9736% | 4,550 0264% | 45.500.264 ppb | 1 / 21,977 895 |
| 2,575 829σ | 99% | 1% | 10.000.000 ppb | 1 / 100 |
| 3σ | 99,730 0204% | 0,269 9796% | 2.699.796 ppb | 1 / 370,398 |
| 3,290 527σ | 99,9% | 0,1% | 1.000.000 ppb | 1 / 1.000 |
| 3,890 592σ | 99,99% | 0,01% | 100.000 ppb | 1 / 10.000 |
| 4σ | 99,993 666% | 0,006 334% | 63.340 ppb | 1 / 15.787 |
| 4,417 173σ | 99,999% | 0,001% | 10.000 ppb | 1 / 100.000 |
| 4,891 638σ | 99,9999% | 0,0001% | 1.000 ppb | 1 / 1.000.000 |
| 5σ | 99,999 942 6697% | 0,000 057 3303% | 573,3303 ppb | 1 / 1.744.278 |
| 5,326 724σ | 99,999 99% | 0,000 01% | 100 ppb | 1 / 10.000.000 |
| 5,730 729σ | 99,999 999% | 0,000 001% | 10 ppb | 1 / 100.000.000 |
| 6σ | 99,999 999 8027% | 0,000 000 1973% | 1,973 ppb | 1 / 506.797.346 |
| 6,109 410σ | 99,999 9999% | 0,000 0001% | 1 ppb | 1 / 1.000.000.000 |
| 6,466 951σ | 99,999 999 99% | 0,000 000 01% | 0,1 ppb | 1 / 10.000.000.000 |
| 6,806 502σ | 99,999 999 999% | 0,000 000 001% | 0,01 ppb | 1 / 100.000.000.000 |
| 7σ | 99,999 999 999 7440% | 0,000 000 000 256% | 0,002 56 ppb | 1 / 390.682.215.445 |
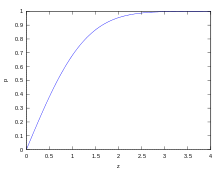
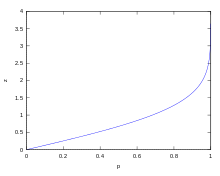
Die Wahrscheinlichkeiten
für bestimmte Streuintervalle ![[\mu -z\sigma ;\mu +z\sigma ]](/svg/a2853d29534da7711f5c3f5b91adcebc26ab18c3.svg) können berechnet werden als
können berechnet werden als
 ,
,
wobei  die Verteilungsfunktion
der Standardnormalverteilung ist.
die Verteilungsfunktion
der Standardnormalverteilung ist.
Umgekehrt können für gegebenes  durch
durch

die Grenzen des zugehörigen Streuintervalls
mit Wahrscheinlichkeit
berechnet werden.
Ein Beispiel (mit Schwankungsbreite)
Die Körpergröße des Menschen ist näherungsweise normalverteilt. Bei einer Stichprobe von 1.284 Mädchen und 1.063 Jungen zwischen 14 und 18 Jahren wurde bei den Mädchen eine durchschnittliche Körpergröße von 166,3 cm (Standardabweichung 6,39 cm) und bei den Jungen eine durchschnittliche Körpergröße von 176,8 cm (Standardabweichung 7,46 cm) gemessen.
Demnach lässt obige Schwankungsbreite erwarten, dass 68,3 % der Mädchen eine Körpergröße im Bereich 166,3 cm ± 6,39 cm und 95,4 % im Bereich 166,3 cm ± 12,78 cm haben,
- 16 % [≈ (100 % − 68,3 %)/2] der Mädchen kleiner als 160 cm (und 16 % entsprechend größer als 173 cm) sind und
- 2,5 % [≈ (100 % − 95,4 %)/2] der Mädchen kleiner als 154 cm (und 2,5 % entsprechend größer als 179 cm) sind.
Für die Jungen lässt sich erwarten, dass 68 % eine Körpergröße im Bereich 176,8 cm ± 7,46 cm und 95 % im Bereich 176,8 cm ± 14,92 cm haben,
- 16 % der Jungen kleiner als 169 cm (und 16 % größer als 184 cm) und
- 2,5 % der Jungen kleiner als 162 cm (und 2,5 % größer als 192 cm) sind.
Schätzung der Standardabweichung der Grundgesamtheit aus einer Stichprobe
Allgemeiner Fall
Berechnungsgrundlagen
Sind die
Zufallsvariablen  unabhängig
und identisch verteilt, also beispielsweise eine Stichprobe,
so wird die Standardabweichung der Grundgesamtheit
der Stichprobe häufig mit der Formel
unabhängig
und identisch verteilt, also beispielsweise eine Stichprobe,
so wird die Standardabweichung der Grundgesamtheit
der Stichprobe häufig mit der Formel

geschätzt. Dabei ist
 die Schätzfunktion für die Standardabweichung
die Schätzfunktion für die Standardabweichung  der Grundgesamtheit
der Grundgesamtheit-
der Stichprobenumfang (Anzahl der Werte)
-
die Merkmalsausprägung am
 -ten
Element der Stichprobe
-ten
Element der Stichprobe  der empirische Mittelwert,
also das arithmetische
Mittel der Stichprobe.
der empirische Mittelwert,
also das arithmetische
Mittel der Stichprobe.
Diese Formel erklärt sich daraus, dass die korrigierte
Stichprobenvarianz  ein erwartungstreuer
Schätzer für die Varianz
ein erwartungstreuer
Schätzer für die Varianz  der Grundgesamtheit ist. Im Gegensatz dazu ist aber
kein erwartungstreuer Schätzer für die Standardabweichung. Da die Quadratwurzel
eine konkave
Funktion ist, folgt aus der Jensenschen
Ungleichung
der Grundgesamtheit ist. Im Gegensatz dazu ist aber
kein erwartungstreuer Schätzer für die Standardabweichung. Da die Quadratwurzel
eine konkave
Funktion ist, folgt aus der Jensenschen
Ungleichung
 .
.
Dieser Schätzer unterschätzt also in den meisten Fällen die Standardabweichung der Grundgesamtheit.
Beispiel
Wählt man eine der Zahlen  oder
oder  durch Wurf einer fairen Münze, also beide mit Wahrscheinlichkeit jeweils
durch Wurf einer fairen Münze, also beide mit Wahrscheinlichkeit jeweils  ,
so ist das eine Zufallsgröße mit Erwartungswert 0, Varianz
,
so ist das eine Zufallsgröße mit Erwartungswert 0, Varianz  und Standardabweichung
und Standardabweichung  .
Berechnet man aus
.
Berechnet man aus  unabhängigen Würfen
unabhängigen Würfen  und
und  die korrigierte Stichprobenvarianz
die korrigierte Stichprobenvarianz

wobei

den Stichprobenmittelwert bezeichnet, so gibt es vier mögliche
Versuchsausgänge, die alle jeweils Wahrscheinlichkeit  haben:
haben:
|
|
 |
|
|
|---|---|---|---|---|
|
|
|
 |
|
|
|
|
 |
 |
|
|
|
|
|
|
|
|
|
|
Der Erwartungswert der korrigierten Stichprobenvarianz beträgt daher
 .
.
Die korrigierte Stichprobenvarianz ist demnach also tatsächlich erwartungstreu. Der Erwartungswert der korrigierten Stichprobenstandardabweichung beträgt hingegen
 .
.
Die korrigierte Stichprobenstandardabweichung unterschätzt also die Standardabweichung der Grundgesamtheit.
Berechnung für auflaufende Messwerte
In Systemen, die kontinuierlich große Mengen an Messwerten erfassen, ist es oft unpraktisch, alle Messwerte zwischenzuspeichern, um die Standardabweichung zu berechnen.
In diesem Zusammenhang ist es günstiger, eine modifizierte Formel zu
verwenden, die den kritischen Term  umgeht. Dieser kann nicht für jeden Messwert sofort berechnet werden, da der
Mittelwert
umgeht. Dieser kann nicht für jeden Messwert sofort berechnet werden, da der
Mittelwert  nicht konstant ist.
nicht konstant ist.
Durch Anwendung des Verschiebungssatzes
und der Definition des Mittelwerts  gelangt man zur Darstellung
gelangt man zur Darstellung
![\begin{align}
s & = {} \sqrt{\frac{1}{n-1} \left[\left(\sum_{i=1}^n x_i^2\right) - \frac{1}{n}\left(\sum_{i=1}^n x_i\right)^2\right]}
\end{align}](/svg/757e04c18079f8de79b0b3d2d8348334cf59465e.svg)
die sich für jeden eintreffenden Messwert sofort aktualisieren lässt, wenn
die Summe der Messwerte  sowie die Summe ihrer Quadrate
sowie die Summe ihrer Quadrate  mitgeführt und fortlaufend aktualisiert werden. Diese Darstellung ist allerdings
numerisch weniger stabil, insbesondere kann der Term unter der Quadratwurzel
numerisch durch Rundungsfehler kleiner als 0 werden.
mitgeführt und fortlaufend aktualisiert werden. Diese Darstellung ist allerdings
numerisch weniger stabil, insbesondere kann der Term unter der Quadratwurzel
numerisch durch Rundungsfehler kleiner als 0 werden.
Normalverteilte Zufallsgrößen
Berechnungsgrundlagen
Für den Fall normalverteilter Zufallsgrößen lässt sich allerdings ein erwartungstreuer Schätzer angeben:

Dabei ist
die Schätzung der Standardabweichung und  die Gammafunktion. Die Formel
folgt indem man beachtet, dass
die Gammafunktion. Die Formel
folgt indem man beachtet, dass  eine Chi-Quadrat-Verteilung
mit
eine Chi-Quadrat-Verteilung
mit  Freiheitsgraden hat.
Freiheitsgraden hat.
| Stichprobenumfang | Korrekturfaktor |
|---|---|
| 2 | 1,253314 |
| 5 | 1,063846 |
| 10 | 1,028109 |
| 15 | 1,018002 |
| 25 | 1,010468 |
Beispiel
Es wurden bei einer Stichprobe aus einer normalverteilten Zufallsgröße die fünf Werte 3, 4, 5, 6, 7 gemessen. Man soll nun die Schätzung für die Standardabweichung errechnen.
Der Stichprobenvarianz ist:

Der Korrekturfaktor ist in diesem Fall

und die erwartungstreue Schätzung für die Standardabweichung ist damit näherungsweise



© biancahoegel.de
Datum der letzten Änderung: Jena, den: 11.12. 2022